이전에는 자막 없는 영상 때문에 자막이 나올 때 까지 기다리는 경우가 많이 있었습니다. 특히 미드나 일드, 일본 애니를 많이 시청하지만 영어나 일본어를 잘 못하는 사람들은 자막이 나올 때 까지 기다려야만 했습니다. 하지만 세상이 좋아져 이제는 AI 자동 자막 생성으로 소리 자체를 해당 언어로 번역하고 그것을 또 바로 번역하여 한글 자막까지 만들어 주는 세상이 왔습니다. 이제 팟플레이어만 있다면 어떤 영상이든 괜찮은 자막 생성으로 괜찮게 번역된 자막을 볼 수 있습니다.
실제 번역은 OpenAI의 Whisper 자동 음성 인식 모델을 사용하는 것 이지만 팟플레이어에서 이것을 쉽게 이용 가능하도록 해주고 있습니다. 간편하게 가능하므로 몇 가지 설정만 확인하고 따라해보세요.
AI 자동 자막 생성 방법
팟플레이어 설치
https://tv.kakao.com/guide/potplayer 에 들어가 다운로드 받고 설치를 합니다.
팟플레이어 소리로 자막 생성 설정 방법

팟플레이어 화면 우클릭 → 자막 → 소리로 자막 생성 → 소리로 자막 생성…
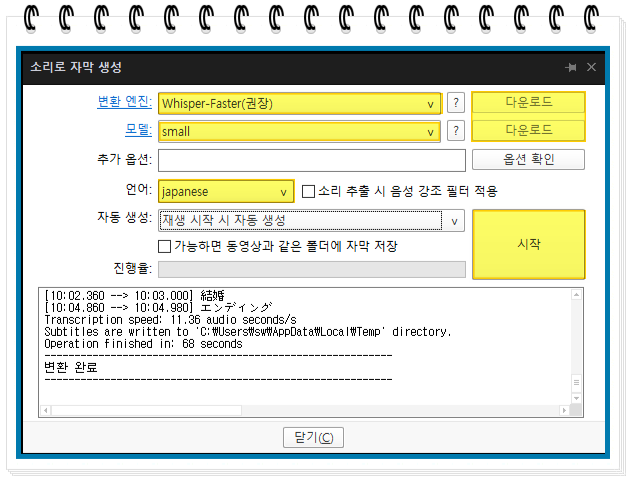
변환 엔진과 모델을 설정합니다.
변환 엔진은
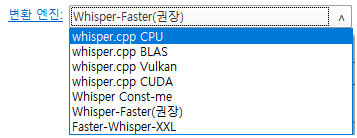
whisper-Faster를 선택하는 것을 권장합니다.
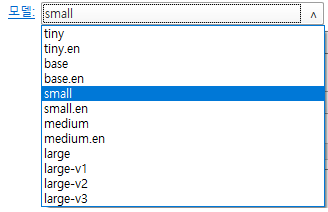
모델은 small을 선택하는 것을 권장합니다.
변환 엔진 선택 후 오른쪽의 다운로드를 눌러 설치를 해줍니다.
그리고 시작 버튼을 누릅니다.
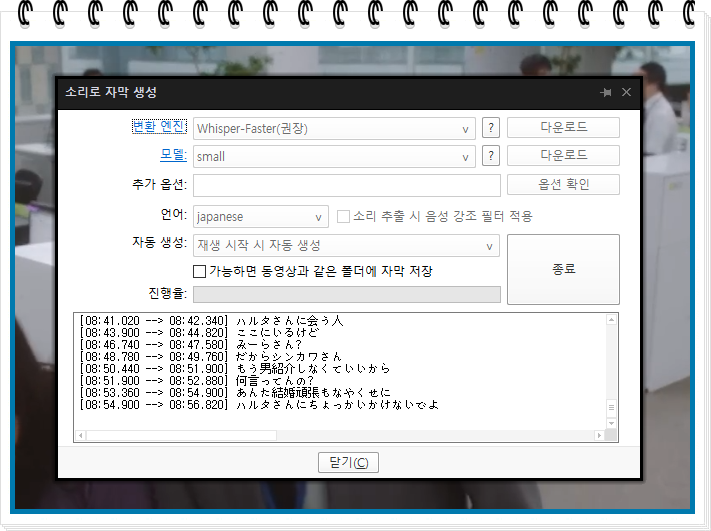
자막이 생성되고 시작 버튼은 종료 버튼으로 바뀝니다. 이제 닫기를 누르고
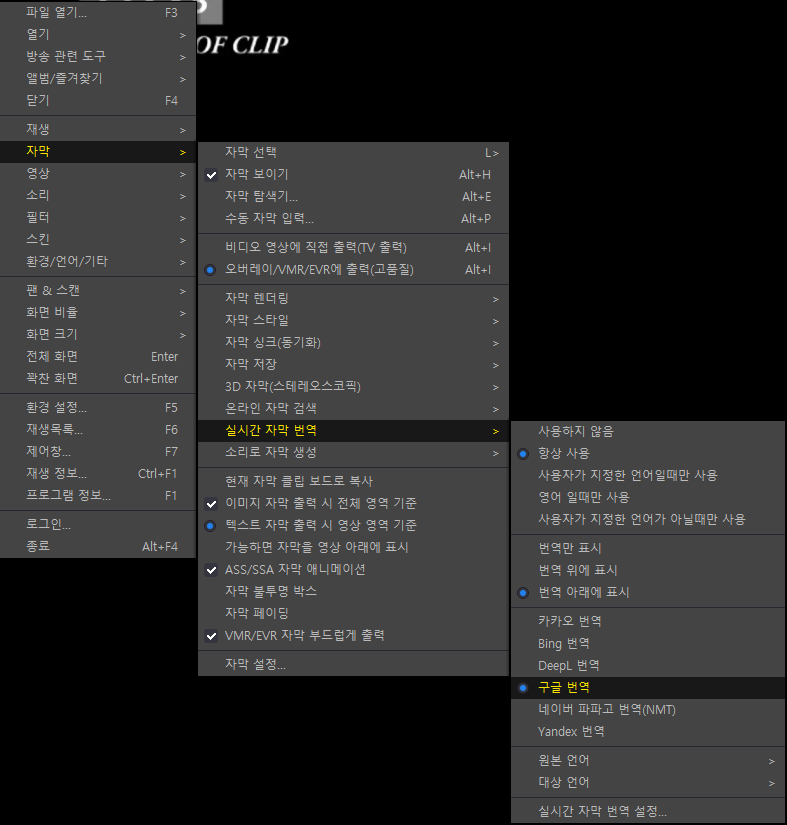
화면 우클릭 → 자막 → 자막 보이기 (체크), 실시간 자막 번역 → 항상 사용(체크), 번역 아래에 표시(또는 번역만 표시 체크), 구글 번역(체크)
위와 같이 설정하고 재생을 하면 끝 입니다.

whisper-Faster 엔진과 small 모델을 선택한 후 결과입니다. 노란색박스를 친 곳이 소리로 생성된 자막을 번역한 내용이고 밑의 내용은 영상 자체에 있던 영어 자막입니다. 번역이 잘 됨을 확인할 수 있었습니다.
안봐도 되는 내용 – 궁금한 사람을 위한 설정 관련 설명
설정과 관련된 추가 내용
whisper 변환 엔진
🔧 Whisper 변환엔진 비교표
| 엔진 이름 | 설명 | 특징 | 권장 환경 |
|---|---|---|---|
cpu | 일반 CPU 연산 | GPU 없는 환경에서 사용 | 저사양 PC, 서버 등 |
blas | CPU 최적화 수학 라이브러리 (BLAS) 사용 | CPU 사용 시 성능 향상 | CPU 환경 중 좀 더 빠른 연산 원할 때 |
vulkan | GPU 가속을 Vulkan API로 수행 | 다양한 GPU에서 작동, 비교적 가벼움 | AMD GPU, 내장 GPU 환경 |
cuda | NVIDIA 전용 GPU 연산 | 가장 빠르고 효율적인 GPU 추론 | NVIDIA GPU 사용자 |
faster | ONNX 기반 faster-whisper 엔진 | 빠르고 메모리 효율적 | 모든 사용자에게 추천 |
const-me | 실험용 커스텀 백엔드 | 특정 상황에 최적화 | 실험적 사용 또는 고급 사용자 |
xxl | 초대형 모델용 (백엔드가 아니라 모델 크기 의미) | 높은 정확도, 느림, 고사양 필요 | A100, RTX 3090 이상 GPU |
🔍 각 백엔드 옵션 자세히 보기
1️⃣ cpu / blas
GPU가 없을 경우 기본적으로 사용하는 엔진입니다. 느리지만 환경 제약이 적습니다. blas는 CPU 환경에서도 속도를 조금 더 높일 수 있는 라이브러리 기반의 옵션입니다.
2️⃣ cuda
NVIDIA GPU에서 최고의 성능을 보이는 백엔드입니다. RTX 3060 이상의 GPU에서 매우 빠른 음성 인식이 가능합니다. 단, CUDA Toolkit과 드라이버가 잘 설치되어 있어야 합니다.
3️⃣ vulkan
NVIDIA가 아닌 GPU (예: AMD, Intel 내장 GPU 등)를 사용할 수 있는 GPU 가속 엔진입니다. Vulkan은 범용 GPU API라 다양한 환경에서 작동합니다.
4️⃣ faster
faster-whisper라는 이름으로 유명한 ONNX 기반의 엔진입니다. PyTorch 대비 메모리 사용량이 적고 속도가 빠릅니다. 고용량 모델도 상대적으로 잘 돌아가는 것이 특징입니다.
5️⃣ const-me
공식적으로는 알려진 바가 적지만, 일부 고급 사용자가 사용하는 실험적인 엔진입니다. 모델 크기 줄이기나 추론 최적화에 사용됩니다.
6️⃣ xxl
사실 xxl은 백엔드라기보다 Whisper 모델 중 가장 큰 사이즈를 의미합니다. 최고의 정확도를 제공하지만 리소스를 많이 소모하며 느립니다.
💡 어떤 백엔드를 선택해야 할까?
| 사용 목적 | 추천 백엔드 |
|---|---|
| 일반 사용자 | faster, cuda |
| GPU 없는 환경 | cpu, blas |
| AMD 또는 내장 GPU 사용자 | vulkan |
| 속도보다 정확도가 중요 | xxl (with cuda) |
| 실험 또는 고급 최적화 | const-me |
Whisper는 AI 음성 인식 분야에서 뛰어난 정확도와 유연성으로 주목받고 있습니다. 특히 OpenAI에서 공개한 다양한 모델 크기(tiny, base, small, medium, large-v3)는 사용자의 환경과 목적에 맞게 선택할 수 있도록 설계되어 있습니다.
그렇다면 각 모델의 차이점은 무엇이며, 어떤 모델을 선택하는 것이 좋을까요?
Whisper 모델
📊 Whisper 모델 비교표
| 모델명 | 크기(파라미터) | 속도 🚀 | 정확도 🎯 | 용도 추천 |
|---|---|---|---|---|
tiny | ~39M | 매우 빠름 | 낮음 | 빠른 테스트, 저사양 환경 |
base | ~74M | 빠름 | 보통 | 단기 프로젝트, 속도 우선 |
small | ~244M | 보통 | 준수함 | 일반적 용도, 실시간도 가능 |
medium | ~769M | 느림 | 높음 | 자막 생성, 콘텐츠 제작 |
large-v2 | ~1550M | 매우 느림 | 매우 높음 | 최종 품질, 정확도 우선 |
large-v3 | ~1550M | 매우 느림 | 최고 정확도 | 긴 오디오, 외국어 번역 등 |
※ 모델 크기(M)는 파라미터(Parameter) 수를 나타냅니다. 파라미터가 많을수록 정확도는 높지만 처리 속도와 메모리 사용량도 증가합니다.
🧠 어떤 모델을 선택해야 할까?
Whisper의 모델은 크게 속도 ↔ 정확도의 균형을 기준으로 선택하면 좋습니다.
- 속도 중요 →
tiny또는base- 유튜브 요약, 테스트용, 실시간 변환
- 일반적인 음성 인식 →
small- 자막 제작, 팟캐스트 전사
- 정확도가 중요 →
medium,large-v3- 방송용 콘텐츠, 유튜브 자막, 번역 포함 인식
⚙️ 시스템 요구 사항은?
| 모델 | 최소 권장 GPU (RAM 기준) |
|---|---|
tiny, base | 2GB 이상 VRAM |
small | 4GB VRAM 이상 |
medium | 8GB VRAM 이상 |
large-v3 | 12GB 이상 권장 (16GB 이상 추천) |
CPU에서도 작동하지만 속도가 많이 느려질 수 있으므로 GPU 사용을 강력히 권장합니다.
faster-whisper와 조합하면 더 쾌적하게
faster-whisper ONNX 엔진을 사용하면, large 모델도 상대적으로 더 가볍고 빠르게 처리할 수 있습니다. 메모리 사용량 최적화가 잘 되어 있어 저사양에서도 큰 모델을 활용할 수 있는 가능성이 커집니다.
처음 접하시는 분이라면 small로 시작해보세요. 익숙해진 후엔 large-v3까지 천천히 올려가며 테스트를 해보세요. large 모델의 경우에 시간 재벌에게 추천하는 모델입니다.
뒤의 모델을 쓸 수록 정확도는 높아지지만 걸리는 시간이 늘어나므로 적절한 모델을 선택해 쓰는 것이 가장 좋습니다.
AI 관련 글